
这一章我们主要学习关于页面导航,网络请求以及数据缓存的知识,学习如何在跨页面中传递参数,如何拦截请求等
# 页面导航
说到页面导航,我们可能首先想到的是页面跳转(页面A跳转到页面B),页面跳转在不同端之间有不同的区别:
- H5 通过 window.history 属性对其进行访问,改变路由记录从而实现跳转
- ios/安卓 是改变根视图或操作导航控制器出栈进栈从而实现跳转
- 小程序实现跳转采用的方式也是改变根视图或操作导航控制器出栈进栈
如果你要把用 Uniapp 开发的项目编译成 H5,那么该项目呈现的是单页面应用,单页面应用实现页面跳转是通过监测页面 url 的 hash 改变而加载不同页面。hash 模式背后的原理是 onhashchange 事件,可以在 window 对象上监听这个事件:
window.location.hash = 'list/list' // 设置页面 url 的 hash,会在当前url后加上 '#list/list'
let hash = window.location.hash // '#/pages/list/list'
window.addEventListener('hashchange', function(){
// 监听 hash 变化,点击浏览器的前进后退或者hash改变会触发
})
@前端进阶之旅: 代码已经复制到剪贴板
例如访问列表地址,# 后面的路径就是指向页面地址:
http://localhost:8080/#/pages/list/list
@前端进阶之旅: 代码已经复制到剪贴板
如果不想要很丑的 hash,我们可以用路由的 history 模式,在项目的配置文件 【manifest.json】>>【h5配置】>> 【路由模式】 进行修改:
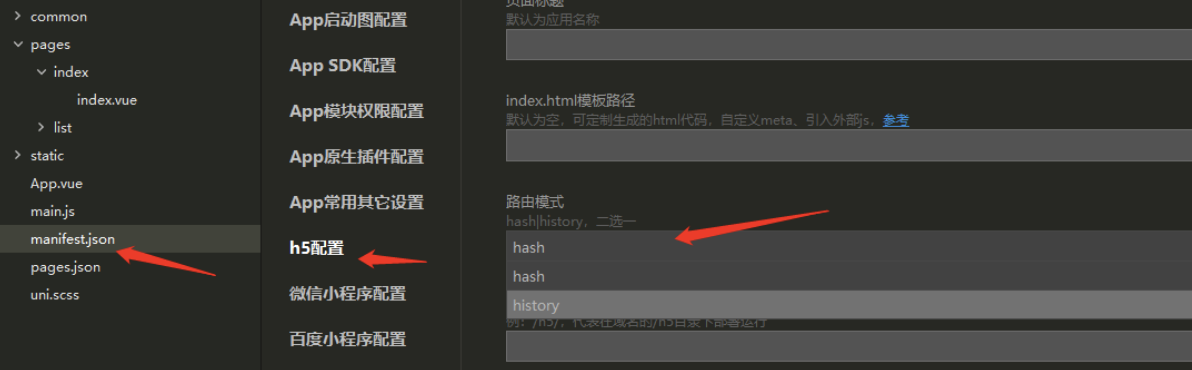
history 模式改变 url 的方式会导致浏览器向服务器发送请求,如果服务器端未做任何处理,则会请求资源失败,我们需要在服务器端做处理:如果匹配不到任何静态资源,则应该始终返回同一个 html 页面。具体操作可以看这里
如果你要用 Uniapp 开发的项目编译成微信小程序,就要注意微信小程序的页面栈的限制了,小程序中页面栈限制最多十层(微信进行了限制调整),随着页面栈的push增加,在不知道的情况下就会堆栈到十层,再用API navigateTo 去跳转页面就跳不动了,用户会跳转失效(卡死状态)。
如果遇到上述问题,删除当前页面栈(redirectTo)或删除所有页面栈(reLaunch)来跳转了,页面栈以跳转的 url 为第一个页面栈。页面栈可以通过 getCurrentPages 方法获取。
function navigateTo(url, callback) {
let goType = getCurrentPages().length >= 10 ? 'redirectTo' : 'navigateTo'
wx[goType]({
url,
success: res => {
callback()
},
fail: res => { },
complete: res => { },
})
}