
# 认识数据:What
该模型的第一部分是认识数据,也就是认识我们可视化的对象:数据。
认识数据的核心就是确定数据的类型,只有正确地认识数据类型才能选择正确的可视化方法。比如分类数据就应该用差别比较大的颜色去可视化,如果用连续的颜色去可视化就会带来错误的信息。现实生活的数据是复杂多层次的,不同的层次有不同的分类方法,这是认识数据的难点所在。
总的来说数据分为三个层次:数据集、数据和属性,这里需要说明一下层次中的数据和前面提到的数据是不一样的:前面是一个统称,这里的是具体的实例。数据是由一些数据集(DataSet) 构成的,数据集又是由一条条数据(Data) 构成的,每一条数据是由属性(Attribute) 构成的。接下来我们就分别看看它们对应的类型。
# 数据集类型
在信息可视化中,数据集主要分为:表格(Table) 、网络(Network) 和几何(Geometry) 。下面是《Visualization Analysis & Design》的一个解释它们的形象的插图。
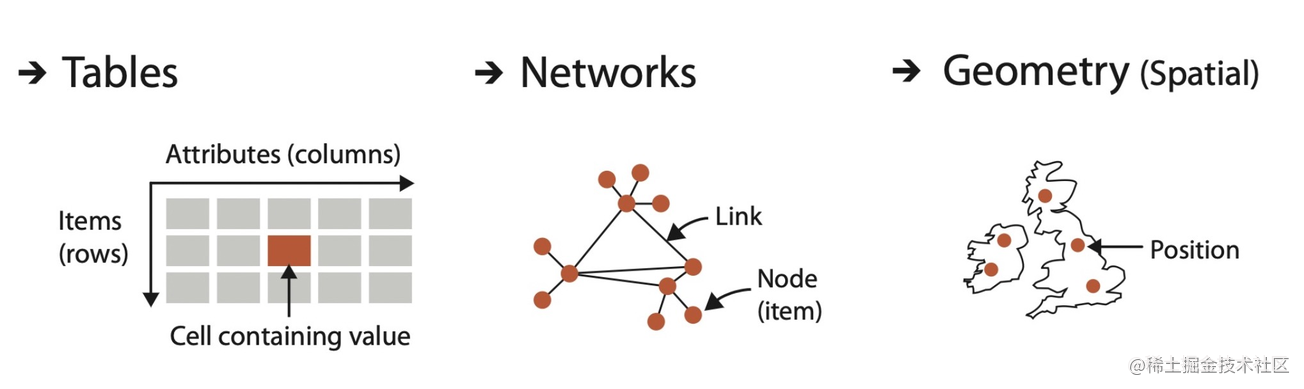
表格想必大家都不陌生,是由行(Row)和列(Col)构成。对于一个一维表格(Flat Table)来说,每一行是一个实体( Item ) ,每一列是该实体的一个属性(Attribute ) 。《苏菲的世界》数据集中的philosophers.json,schools.json 和 questions.json 都是表格,因为它们的每一行都代表了一个实体,这些实体分别是:哲学家、哲学流派、哲学问题。下面用 philosophers.json 中的一条哲学家实体举例:
| id | name | birthday | last day | country | points |
|---|---|---|---|---|---|
| 75 | 苏格拉底 | -470 | -399 | 雅典 | [“我只知道一件事情,那就是我一无所知”, “…”] |
这表格的一行表示:编号 75 的哲学家名叫苏格拉底,他出生于雅典,生于公元前 470 年,死于公元前 339 年,他的其中一条哲学观点是:“我只知道一件事情,那就是我一无所知”。
说完了表格,我们来看看网络数据。网络数据主要用来表示实体之间的关系,在网络中的实体往往被称作为节点( node ) ,节点之间的关系被称作为链接(link) 。《苏菲的世界》数据集中的 relations.csv 就是一个网络,因为它有作为节点的哲学家和哲学流派,也有表示它们关系的链接。下面就是其中一条数据,我们以它为例:
| from | to | type |
|---|---|---|
| 151 | 66 | 0 |
上面的 from 和 to 分别代表两个节点的编号,其中编号为151的节点是哲学中的自然学派,编号为66的节点是哲学家泰利斯,type 为0表示这条链接是流派和哲学家的关系,也就是这条数据表示:泰利斯属于自然学派,也就是说他是一个自然学派的哲学家。
聊完了网络数据,最后我们里看看几何数据。几何数据用构成这个东西的点的位置(Position) 去描述一个实体的形状,这些实体可能是点,线,平面等。在《苏菲的世界》数据集合中,country.json 就是一个几何数据,因为它描述了每个国家的位置和形状的数据。其中 "centroid": [35.55686145836136, -17.30493389122804] ,就是国家的位置经纬度数据。coordinates": []里面的数据就是国家的形状数据。
# 数据类型
了解完数据集的类型,我们来看看构成它的数据的类型。其实在上面数据集类型的介绍中已经提到了不少类型了,那在信息可视化中,数据的主要种类是:实体( Item ) 、链接(Link)、位置(Position) 和属性(Attribute) 。下面的插图展示了表示数据集和数据的之间的关系。

实体是一个单独的个体,比如表格中的一行,网络中一个节点。可以是一个人,也可以是一只蚂蚁,上面的 (75, '苏格拉底', -470, 399, '雅典', ["我只知道一件事情..."]) 其实就是一个实体,因为它描述了“苏格拉底”这个哲学家的一些基本信息。
链接是实体之间的关系(Relationship),比如上面提到的 relations.csv 中的 (151, 66, 0),因为它将对应编号的两个节点链接起来了,并且指明了链接的类型。
位置是空间数据,描述二维或者三维空间的一个位置,比如上面提到的 country.csv 中的 (38, 24) 就是一个位置,因为它描述了雅典这个国家的地理位置。
# 属性类型
其实,不仅仅数据有类型,构成数据的属性同样有类型。
属性是一个可以被测量、观察和记录的特性,所有的实体、链接和位置都由属性构成。属性又被称为变量(Variable) 或者数据维度(Data Dimension) 。
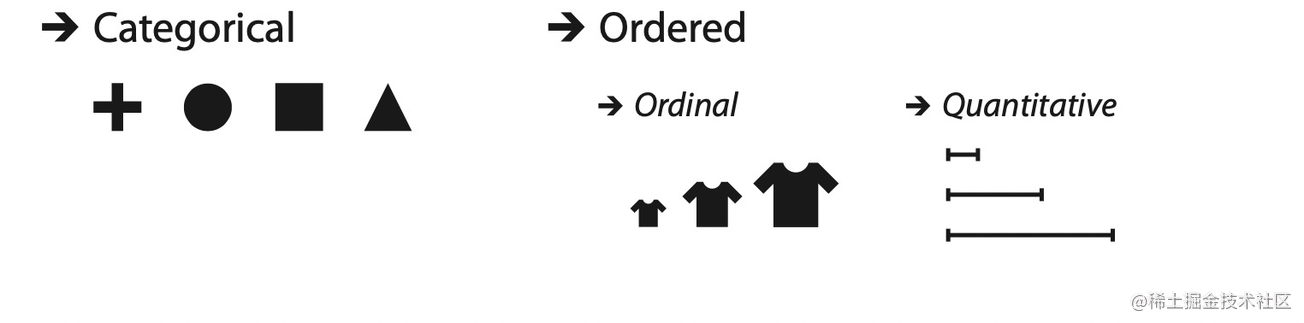
属性可以分为分类属性(Categorical) 和可排序属性(Ordered) 。分类数据不能排序,比如对于上面任何一条哲学家的数据来说:name 和 country 不能排序,都算是分类属性。可排序的数据都具有显示的排序方法,比如 birthday 和 last day 可以直接根据年份大小排序,所以是可排序的数据。
对于可排序的属性来讲,又可以分为序数属性(Ordinal) 和数值属性(Quantitative) 。序数属性本身不能通过计算来排序,但是存在一个约定俗成的排序方法,比如衣服的尺码,它们的排序规则就是:XXL > XL > L > M > S。相对来讲,数值属性可以直接通过计算来排序,比如上面提到的 birthday 和 last day 就可以直接根据年份大小排序。
大家可以通过下面书中的插图感受一下它们的区别。
对于可排序的属性来讲,它们还可以按照方向去排序:顺序属性(Sequential) 、发散属性(Diverging) 和周期属性(Cyclic) 。
顺序属性往往有一个最大值和最小值,比如上面数据中的 id 属性,最大值是 171,最小值是 0。
发散属性往往是两个方向相反的序列在一个零点相遇,比如上面的 birthday,因为年份分为公元前和公元后,是两个相反的序列,同时它们的零点就是公元零零年。周期属性在增加到一定程度之后就不会增加了,会回到原点,比如上面的 longitude 和 latitude 都是周期属性,因为它们增加到 180 度之后都会回到0度,也就是上面提到的原点。
下面的书中的插图形象展示了它们的区别。

# 确定任务:Why
当认识了手中的数据之后,接下来就是确定任务了,这也是我们数据模型的第二部分。
在描述任务的时候往往会存在一个挑战:不同领域有不同的术语,但是在数据分析